Introduction
Dans la première partie de cette série d’articles de blog axés sur la CTI, nous avons introduit le cycle de production du renseignement et proposé une architecture fonctionnelle et technique pour une plateforme de renseignement sur les cybermenaces intégrée et prenant en charge les opérations SOC et de réponse aux incidents (IR).
Cette deuxième partie se concentrera sur la manière dont la Cyber Threat Intelligence peut contribuer et soutenir les activités de chasse aux menaces et d’ingénierie de détection du SOC à travers une activité ciblée de Threat Actor Intelligence.
Rappel : intelligence sur les cybermenaces
Comme nous l’avons vu précédemment, le processus de production de Threat Intelligence peut être représenté comme un processus cyclique en 5 étapes :
- Planification et orientation : besoins en matière de renseignement produit
- Collecte : collecte de données brutes
- Traitement & Exploitation : synthèse et standardisation des données brutes
- Analyse & Production : production de renseignement à partir de données standardisées
- Diffusion : livraison des renseignements produits
Qu’est ce que le Threat Hunting & la détection de menaces
L’ingénierie de détection et le threat hunting peuvent tous deux être considérés comme des activités cruciales dans les opérations SOC modernes. Bien que leur importance soit largement acceptée, la définition associée et les activités inhérentes se chevauchent souvent. Les définitions fournies par Kostas dans son article « Threat Hunting Series : Detection Engineering VS Threat Hunting » met en évidence la différence entre ces deux concepts :
Le Threat hunting est une pratique proactive consistant à rechercher des preuves d’activités adverses que les systèmes de sécurité conventionnels peuvent manquer. Cela implique de rechercher activement des signes de comportement malveillant et des anomalies dans un réseau ou des hôtes individuels. L’ingénierie de détection, quant à elle, est le processus de développement et de maintenance de méthodes de détection permettant d’identifier une activité malveillante une fois qu’elle est connue.
Dans cet article de blog, nous tenterons de donner un aperçu de la manière dont nous avons conçu notre processus de production de renseignements pour alimenter et orienter les efforts de Threat Hunting et d’ingénierie de détection au sein des opérations SOC.
Identifier les acteurs de la menace et extraire les TTP pertinents
Planification et orientation : identifier l’acteur de menace sur lequel se concentrer
L’identification des acteurs de la menace sur lesquels se concentrer est essentielle pour fournir des renseignements précieux et exploitables aux opérations SOC et IR. Avec des ressources limitées, il est évident que l’équipe CTI ne peut pas produire une analyse approfondie de tous les acteurs de la menace actuellement actifs.
Pour s’orienter et prioriser les différents acteurs de la menace, on peut décider d’utiliser différents CTIP gratuits qui fournissent des CTI stratégiques associés à un acteur de la menace donné, tels que :
NB: Si vous possédez votre propre CTIP vous baserez évidemment votre analyse sur ce que vous savez déjà ; cependant, il peut toujours être utile de croiser et d’analyser plusieurs sources.
En utilisant des informations telles que la victimologie (secteurs et pays ciblés), le niveau de sophistication, la récence des activités,… vous pouvez ici identifier une sous-liste de groupes intéressants qui constituent des menaces pertinentes pour votre entreprise. Vous pouvez également compter sur des partenaires de confiance, comme les autorités nationales, pour vous apporter un recul supplémentaire et éventuellement identifier des acteurs de menace spécifiques.
À partir de là, vous pourrez peut-être déjà commencer vos fouilles. Cependant, si vous souhaitez faire quelque chose de plus académique et être capable de communiquer vos décisions, vous pouvez essayer d’utiliser Le modèle Threat Box de SANS introduit par Andy Piazza en 2020 pour évaluer la pertinence de chaque acteur de la menace pour la ou les entités que vous souhaitez protéger.
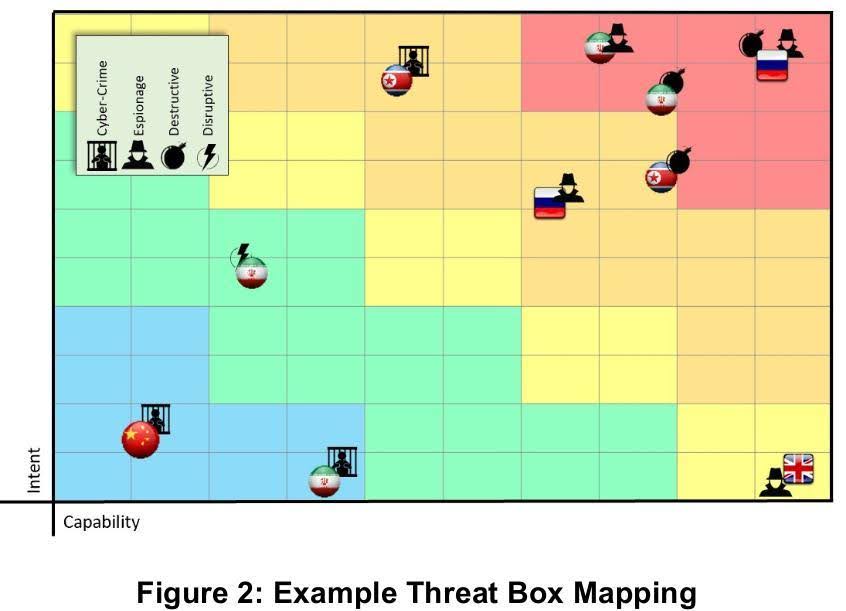
Vous disposez désormais d’un document clair et facile à présenter étayant votre décision de travailler sur des menaces spécifiques ; Venons-en au travail de bibliothécaire : la bibliographie de chaque acteur de la menace.
Collection : bibliographie spécifique aux acteurs de la menace
Comme vous l’avez peut-être deviné, cette phase consiste à répertorier toutes les ressources disponibles, qu’il s’agisse de publications et d’articles officiels ou de rapports IR internes, de détections SOC ou d’informations partagées TLP RED dont vous disposez sur un adversaire spécifique.
Il n’y a pas grand chose à développer ici, mais il est important de choisir et de se concentrer sur un calendrier déterminé pour construire votre backlog (c’est-à-dire où s’arrêter dans le temps) : lorsqu’un adversaire existe depuis plus d’une décennie, les articles plus anciens peuvent être obsolètes, avec des méthodologies et des modèles d’attaque en constante évolution. Cela permet également de ne pas se laisser submerger par la quantité d’informations disponibles
Pour notre première itération de ce processus, nous avons décidé de commencer avec un retard de deux ans, car nous nous concentrions sur des adversaires actifs et largement documentés et souhaitions développer nos activités.
Traitement et analyse : extraction du TTP et identification des opportunités de chasse
Maintenant que vous avez défini et répertorié toutes les ressources liées à votre adversaire dont vous souhaitez extraire, vous devez creuser. Cette extraction TTP n’est pas une « simple » cartographie MITRE ATT&CK de techniques mises en avant (ou déjà taguées) dans les articles techniques ciblés. Au lieu de cela, vous devez approfondir, comprendre quelle technique l’adversaire a utilisée et comment elle a été mise en œuvre ; tout en vous demandant comment rechercher (c’est-à-dire interroger les données collectées) un tel comportement.
Cela implique souvent de lire un article plusieurs fois, de se concentrer sur les ressources fournies telles que des captures d’écran techniques et de recourir à des sources externes pour comprendre ce qui est présenté.
Ce faisant, vous serez en mesure de constituer un bon inventaire TTP axé sur la chasse et lié à votre adversaire ; de préférence dans un format standardisé.
Prenons un exemple réel avec l’Article de Volexity sur Charming Kitten publié en juin 2023. Cet article fournit à la fois un aperçu clair des opérations récentes de Charming Kitten et une analyse approfondie de leur porte dérobée baptisée POWERSTAR. Dans la section « Analyse de la porte dérobée » il est mentionné que :
Fait intéressant, alors qu’une clé AES et IV sont définies dans la configuration d’origine, Volexity a observé que le C2 mettait à jour dynamiquement la clé après le trafic initial de la balise. De plus, POWERSTAR définit le IV sur une valeur aléatoire, puis la transmet au C2 via l’en-tête « Content-DPR » de chaque requête. Dans les versions précédentes de POWERSTAR, au lieu d’AES, un chiffrement personnalisé était utilisé pour coder les données pendant le transit. L’adoption d’AES pourrait être considérée comme une amélioration du fonctionnement du malware par rapport aux versions précédentes.
À première vue, on pourrait remarquer le changement de mécanisme de cryptage dans POWERSTAR et extraire ce nouveau TTP comme suit :
Ce qui est génial, mais y a-t-il autre chose à extraire ici ? Nous devrons peut-être nous poser quelques questions supplémentaires.
Regardons cela à nouveau, l’article précise que «POWERSTAR procède à la définition du IV sur une valeur aléatoire, puis la transmet au C2 via l’en-tête « Content-DPR » de chaque requête .
→ Cette implémentation est-elle spécifique à l’activité POWERSTAR C2 ?
→ Qu’est-ce que l’en-tête Content-DPR
→ Est-ce couramment utilisé ?
→ Qu’est-ce qui y est habituellement stocké ?
Selon la Documentation du développeur Mozilla, cet en-tête est obsolète et est couramment utilisé pour «pour confirmer le rapport périphérique d’image/pixel dans les demandes où l’indice du client DPR d’écran a été utilisé pour sélectionner une ressource d’image.». Les valeurs courantes semblent être des nombres compris entre 0 et 100.
POWERSTAR stocke les valeurs du vecteur initial AES dans cet en-tête, qui est un tableau de 128 bits, donc une valeur plus longue et assez anormale à trouver dans cet en-tête.
→ Est-ce pertinent à des fins de chasse ou de détection ?
→ Quelles données sont nécessaires pour avoir une visibilité sur un tel comportement ?
→ Ce type de comportement est-il censé être verbeux ?
La valeur du contenu devrait être inhabituelle ici, et pourrait être traquée via l’inspection des paquets ou des journaux d’inspection du trafic Web particulièrement détaillés. Aussi la documentation précise que, dans le cadre d’une utilisation normale de DPR, « Un serveur doit d’abord s’inscrire pour recevoir l’en-tête DPR en envoyant l’en-tête de réponse Accept-CH contenant la directive DPR. »; on peut également souhaiter rechercher un en-tête Content-DPR non sollicité dans la télémétrie susmentionnée, car la présence de l’en-tête Accept-CH n’est pas mentionnée dans l’article.
De plus, comme cet en-tête est marqué comme obsolète, sa simple utilisation pourrait être un indicateur. Cette hypothèse est un pari, et donc dangereuse pour les opérations. Certaines analyses statistiques au sein de l’environnement de production devraient être utilisées pour évaluer et peut-être éliminer cela.
Dans tous les cas, cela nous donne maintenant l’extraction TTP suivante :
| Nom de l’acteur de la menace |
Source |
Tactique |
Technique |
Détails |
Possibilités de chasse |
Télémétrie requise |
Commentaire / Warning |
| Charming Kitten |
https://www.volexity.com/blog/2023/06/28/charming-kitten-updates-powerstar-with-an-interplanetary-twist/ |
TA0011 Command and Control |
Encrypted Channel: Symmetric Cryptography |
POWERSTAR update now relies on AES cipher rather than custom cipher. |
Abnormal values in “Content-DPR” header
Unsolicited “Content-DPR” header in client response |
SSL – interception with according HTTP header extraction |
Requires specific sensors and configurations.
Possibly resource consuming hunt:’) |
Cet exemple est bien sûr une illustration de la façon dont nous avons essayé d’extraire les TPP et plus particulièrement les opportunités de chasse/détection à l’intérieur des articles CTI. L’identification des opportunités de chasse et de détection est une tâche complexe et subjective ; vous pourriez être en désaccord avec ce que nous venons d’extraire. Le but était de mettre en évidence les différentes questions que nous nous sommes posées et le type d’informations supplémentaires que nous avons essayé d’extraire avec les TTP « standards ».
Diffusion : carte mentale et cas d’utilisation de la chasse
Cette dernière partie concerne le formatage et la synthèse de ce que vous venez de produire.
Vous pouvez par exemple créer une carte mentale synthétisée pour créer un aperçu exploitable des TTP et des opportunités de recherche pour un acteur menaçant spécifique :
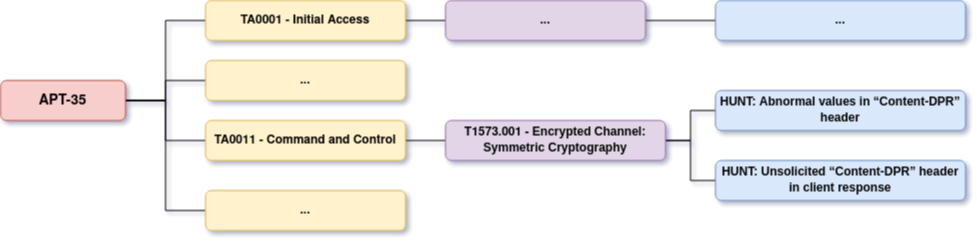
Vous pouvez également ingérer et formater ces connaissances dans votre CTIP si vous en avez un. Mais gardez à l’esprit que l’adaptation au format requis par vos besoins en matière de renseignement peut nécessiter certaines adaptations et compromis.
Informations opérationnelles – du point de vue du MSSP
Avant d’aborder la manière d’exploiter les renseignements décrits ci-dessus, discutons de certaines difficultés opérationnelles auxquelles nous avons été confrontés.
Du point de vue du MSSP, identifier les acteurs de la menace à prioriser était plus facile à dire qu’à faire. En effet, la variété des clients et leurs secteurs d’activité, la géolocalisation,… rendaient assez difficile d’avoir une liste réduite d’acteurs menaçants qui cibleraient nos clients. Nous avons utilisé le modèle ThreatBox et comparé certains « archétypes » de nos clients, mais avec peu de succès. En conséquence, nous avons décidé de sélectionner plusieurs menaces actives et déjà rencontrées pour commencer, et de poursuivre le développement de cette activité. Il est important de noter que nous nous attendons à ce que le modèle ThreatBox soit bien plus pertinent pour les opérations internes SOC/CERT que dans notre cas.
De plus, comme nous n’avions pas de CTIP approprié à l’époque, nous avons documenté manuellement les TTP extraits à l’aide de feuilles de calcul Excel et de versionnement. Ce n’était pas idéal, car nous avions quelques problèmes de collaboration avec cet outil, et le partage avec des équipes externes était manuel et n’offrait pas les fonctionnalités importantes offertes par les outils CTIP telles que la liaison automatique, l’interrogation d’indicateurs,… Nous nous attendons à ce que la modélisation de ces informations dans un CTIP devrait simplifier à la fois la collaboration, le partage et l’utilisation des renseignements produits.
Enfin, il est important de mentionner que lorsque nous développions cette activité, nous n’avions pas de spécification claire des besoins en matière de renseignement produit. Nous nous sommes basés sur des processus existants, connus et documentés, mais nous avons également choisi de commencer par nous concentrer sur les acteurs menaçants. Vous souhaiterez peut-être procéder dans l’autre sens et choisir comme entrée votre montre CTI quotidienne. En d’autres termes, il s’agissait d’un processus expérimental et vous souhaiterez peut-être adapter ce processus comme bon vous semble.
Threat hunting et détection des menaces
Du renseignement à la chasse
Au cours des dernières années, de nouvelles technologies et de nouveaux outils ont ajouté une télémétrie significative au puits dans lequel une équipe SOC peut puiser pour développer ses opérations, tout en facilitant en même temps l’accès. Une adoption plus large de ces fonctionnalités (peut-être par rapport à un combo Sysmon+SIEM) fait pencher la balance. En effet, les EDR, XDR, NDR, modules de sécurité cloud, SOAR, permettent de disposer de plus de sources de données pour des langages de requête puissants, de plus de contextualisation et de plus de capacités à corréler les événements entre eux pour effectuer des requêtes plus complexes. Parallèlement, l’évolution de l’ergonomie facilite l’utilisation de ces outils par les équipes opérationnelles. Ces nouvelles capacités sont pour nous l’occasion rêvée de capitaliser efficacement sur le résultat de la Threat Intelligence.
C’est là qu’interviennent les activités de Threat Hunting et d’ingénierie de détection. Grâce aux nombreux outils dont dispose le SOC, il est possible d’élaborer des requêtes de recherche visant à correspondre aux TTP extraits trouvés par le Threat Intelligence. Ce processus de collaboration peut également être itératif, avec Threat Intelligence ajoutant des TTP au backlog et le Threat Hunting et l’ingénierie de détection consommant ce retard.
Une requête de recherche peut avoir deux objectifs principaux, à la fois pour l’ingénierie de chasse et de détection. La plupart de ces capteurs offrent la possibilité de planifier une détection sur la base d’une requête de recherche ciblant la télémétrie du capteur. Ainsi, toute requête de recherche peut souvent être programmée pour être détectée ou stockée dans une bibliothèque de requêtes de chasse à la disposition des analystes SOC. Une règle de détection (fournie par Detection Engineering) fera partie du système d’alerte SOC et devra être précise, générer une faible quantité de faux positifs et disposer d’une documentation de qualité suffisante pour être qualifiable et exploitable 24h/24 et 7j/7. Tandis que les règles de chasse peuvent avoir une plus grande quantité de résultats ou de résultats statistiques et fonctionnent généralement sur une plus grande quantité de données. La valeur ajoutée de tout cela est la possibilité de retrouver une compromission passée après une session de Threat Hunting et des capacités de détection supplémentaires pour le SOC.
Lorsque nous créons une requête de recherche pour la première fois, nous ne savons pas encore si elle deviendra une requête de chasse ou une règle de détection. La requête est d’abord testée sur un réseau réel supervisé (dans le cas d’un MSSP, sur plusieurs réseaux clients). Les résultats de la requête nous mèneront vers une requête Hunting ou vers une règle de Détection.
Threat Hunting
Le but du Threat Hunting est de revenir délibérément sur les activités passées pour trouver des indices de compromission. Après avoir exécuté des requêtes spécialement conçues pour rechercher certains TTP, nous pouvons examiner les résultats manuellement et les évaluer avec des requêtes supplémentaires et d’autres recherches externes.
Pour ce type de requêtes, il est normal de s’attendre à des activités légitimes dans les résultats. Le travail de Hunting consiste à vérifier que ces activités sont bien légitimes. Une requête de chasse peut être générique et non spécifique tant que le nombre de résultats reste gérable, sinon une agrégation des résultats est possible à des fins d’analyse statistique.
Lorsqu’une requête ne peut pas être transformée en règle de détection, nous décidons alors de l’ajouter à notre collection de requêtes de chasse. La chasse peut être effectuée tout en élaborant la règle. Il est également possible de réexécuter régulièrement l’ensemble de la collection de requêtes, mais nous avons constaté que ce type d’activité prend du temps et a peu de chances d’obtenir des résultats. Enfin, disposer d’un tel ensemble de requêtes est extrêmement utile pour approfondir ses recherches lorsqu’une alerte est générée pour une raison différente ou lors d’une réponse à un incident. C’est là que nous avons trouvé le principal intérêt des requêtes de chasse.
Ingénierie de la détection
Le but d’une règle de détection est d’être utilisée dans un système d’alerte et de lancer une enquête depuis le SOC. Pour y parvenir, il faut absolument renvoyer le moins de comportements légitimes possible et ne s’attaquer qu’aux activités malveillantes.
Si ce n’est pas déjà le cas après la création de la requête, alors une phase de réglage est nécessaire. Le réglage d’une règle de détection consiste à exclure toute activité légitime que la requête pourrait renvoyer et à ajouter des restrictions pour rendre la règle suffisamment spécifique pour renvoyer uniquement les résultats attendus. Une bonne règle de détection ne déclenchera pas trop d’alertes chronophages pour les analystes SOC tout en détectant les comportements attendus.
Ce travail de réglage doit être très exhaustif et nous devons avoir une bonne connaissance du réseau supervisé pour obtenir un bon résultat. Dans notre cas, en tant que MSSP, cela signifie avoir une bonne connaissance du client et de ses activités. Des exemples de réglage pourraient consister à mettre sur liste blanche certains logiciels, noms de comptes ou machines générant trop de faux positifs et connus pour être légitimes.
Déploiement et collaboration
La communication dans un environnement opérationnel est primordiale. Vous ne voulez pas que quelqu’un se déchaîne et déploie des trucs louches sur vos systèmes de détection qui déclenchent votre équipe de garde à 3 heures du matin, sans même une note explicative. Il est notamment important de déterminer le format dans lequel les règles sont écrites (langage propriétaire propre à un capteur ? standard Open Source ? etc.) y compris le style de codage (renommage des champs, commentaires, pivots d’investigation, etc.) ; pour garder une trace de l’état du déploiement sur chaque client ; avoir un versioning des règles et pouvoir suivre les mises à jour. Dans notre cas, nous avons décidé de documenter les cas d’utilisation de chasse en utilisant un format YAML personnalisé au sein d’un projet git. Cela nous a permis de générer automatiquement une documentation de démarque lors de la mise en production.
Nous avons d’abord pensé à suivre la méthodologie TaHiTI pour le reporting et la communication. Mais bien que très intéressant, il ne répondait pas à nos besoins particuliers (TaHiTI est principalement conçu pour rendre compte d’un engagement de Threat Hunting, nous avons essayé de le plier pour suivre notre cycle de développement UC, mais cela s’est avéré trop lourd pour nous dans ce contexte). Nous avons donc décidé d’utiliser Jira, un système de tickets pour les tâches de reporting et de distribution. Chaque TTP chassable reçoit un ticket. Les analystes peuvent ensuite s’attribuer les tickets et commencer à travailler sur une requête. La requête elle-même est partagée entre les différentes équipes sur un référentiel git. La structure du git classe les TTP selon leurs tactiques MITRE ATT&CK et accompagnés d’un fichier de métadonnées écrit en yaml. L’intégration continue est utilisée pour s’assurer de la validité des données et pour construire une documentation basée sur celles-ci. De cette façon, le référentiel compile toutes les informations importantes telles que la version des règles, s’il s’agit d’une règle de chasse ou utilisée pour détecter l’objectif principal de la règle et ce qu’il faut rechercher en cas d’alerte.
Pour la communication externe avec nos clients MSSP, nous fournissons une note de version avec toutes les nouvelles règles de détection disponibles, un point culminant sur certaines requêtes, leur objectif et l’état de déploiement.
En pratique
Prenons un exemple. Dans ce scénario, vous faites partie de l’équipe d’ingénierie de détection/de Threat Hunting. Vous opérez principalement sur des capteurs Endpoint Detection & Response (EDR) qui vous fournissent une télémétrie système étendue et vous permettent d’interagir avec les hôtes surveillés pour rechercher ou corriger de manière proactive.
Votre équipe CTI a fait son travail et identifié le modèle de script de persistance suivant qui a été utilisé dans plusieurs campagnes attribuées APT41 :


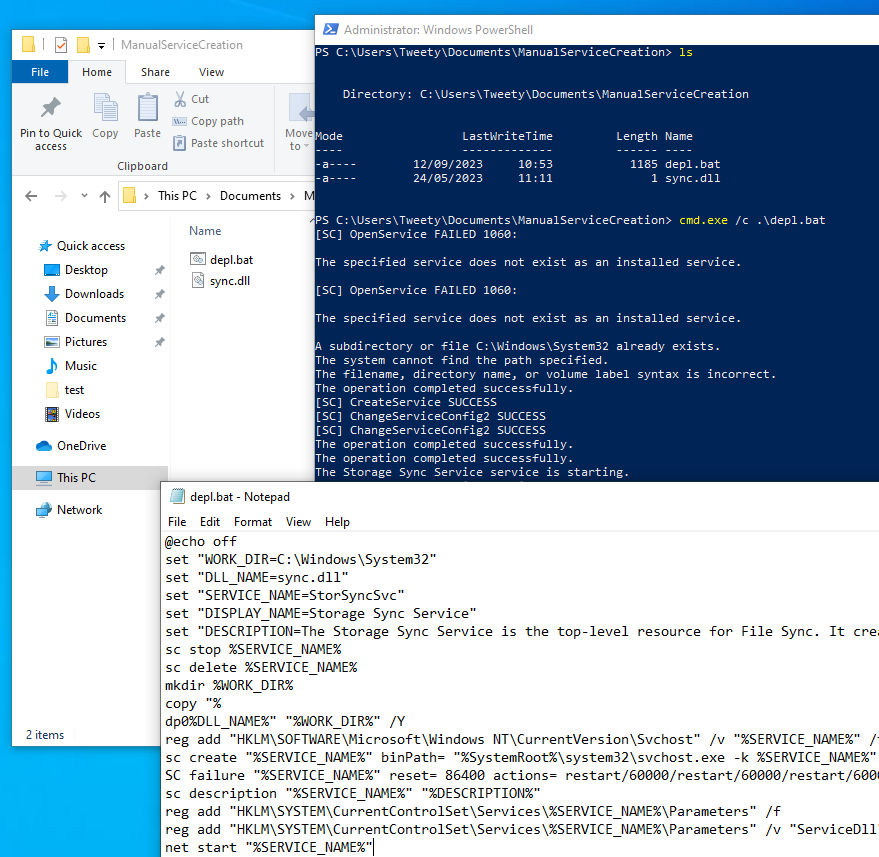
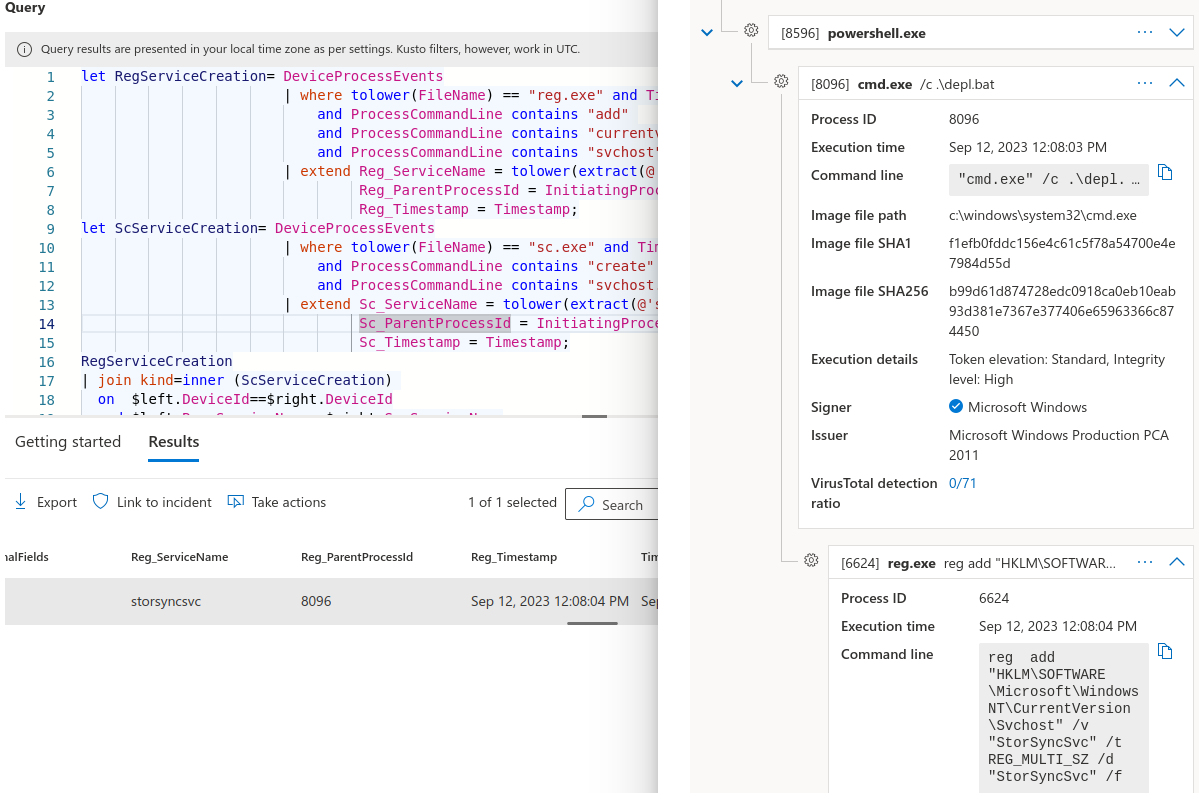
 Cybersécurité
Cybersécurité 
